云+AI的智能时代,传统的大数据架构已经很难满足数据分析的需求,存储逐步从计算中分离出来,以统一的云化存储池来支持海量、多样性数据的存储和分析需求。那么,大数据时代为什么需要云化存储池,云化存储池又需要具备什么样的能力呢?下面,我们就来一探究竟。
为什么需要云化存储池?
现有的大数据系统多以计算存储融合、烟囱式的方式部署,一种大数据应用部署一套独立的大数据集群,这种部署方式在实际应用中遇到了一系列的问题:
首先是不同集群的计算、存储利用率差异较大,资源无法高效利用。大数据场景下,各个大数据集群业务模型不一致,有的是计算密集型,有的是存储密集型,这样就会造成有的集群计算成为瓶颈而存储空闲,有的集群存储成为瓶颈而计算空闲;云化存储池能够很好的解决该问题,实现资源的动态调配。
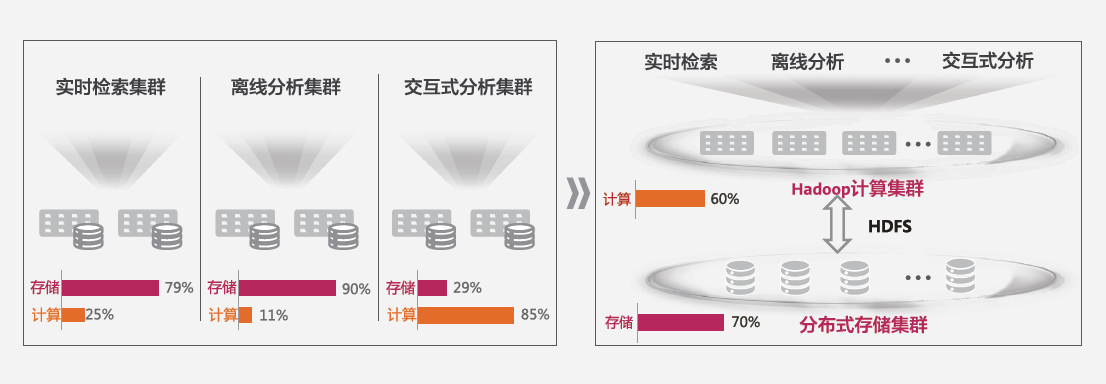
 图1 云化存储池提升资源利用率
图1 云化存储池提升资源利用率
其次是不同集群间数据无法共享,整体分析效率降低。烟囱化部署方式下,一个大数据集群分析的结果要想被另一个集群使用,只能把数据再拷贝一份,既降低了分析效率,又浪费了存储空间;云化存储池可以实现多个大数据集群的数据共享,大幅提升多个大数据集群间协同分析的效率。
最后是业务无法快速上线,不能满足日益多样化的服务需求。烟囱化部署方式下,各种业务相对独立,新业务上线需要采购新的大数据集群,上线周期经常以周甚至月计;云化架构下,计算资源和存储资源都可以随时发放,可以把新业务的上线周期缩短到分钟级。
云化存储池应该具备哪些能力?
自从华为推出大数据存算分离方案,以OceanStor分布式存储作为云化存储池支撑多种大数据应用后,随着以Ceph为代表的开源分布式存储的发展,市面上如雨后春笋般出现了各色的分布式存储产品,那么是否每款分布式存储产品都能作为云化存储池使用呢?
结论肯定不是的,分布式存储只是冰山露出在海面上的一角,要想成为大数据的云化存储池,这款分布式存储还要具备多方面的内涵。下面,我们就来一探“云化存储池”号冰山的内部构成。
1.多命名空间和统一鉴权
一套云化存储池对接多个计算集群,不同的计算集群由于部门归属不同、处理的业务不同,势必要求使用独立的命名空间和鉴权,从而实现数据访问的逻辑隔离,这就要求云化存储池具备多命名空间的能力;计算和存储分离,这就要求存储具备和计算集群统一鉴权的能力。
OceanStor分布式存储支持创建多个命名空间,并支持跟计算集群的统一鉴权。物理空间共享的基础上,每个命名空间跟对应的计算集群采用统一的kerberos、LADP鉴权服务器,同时各命名空间之间的鉴权和数据访问又可以做到逻辑隔离,从而有效支撑多种大数据业务共用云化存储池。
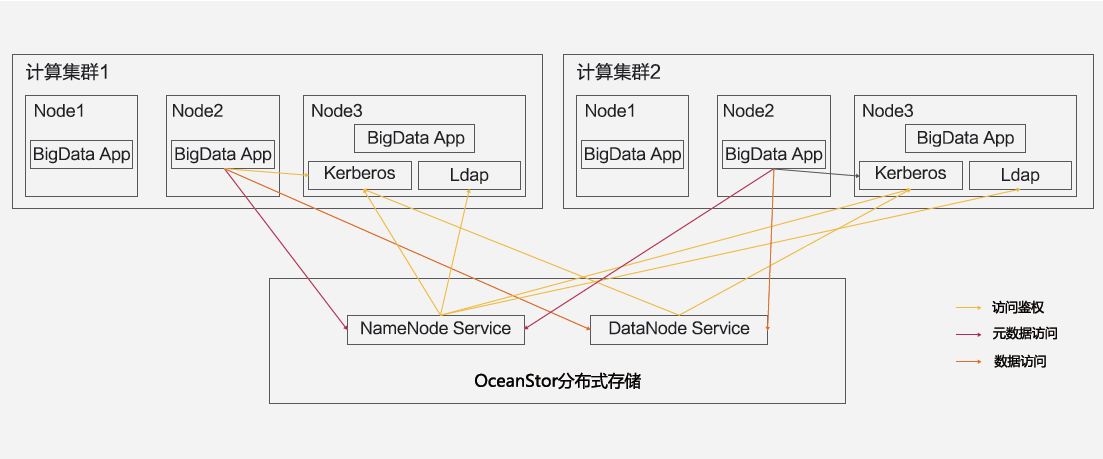 图2 OceanStor分布式存储统一鉴权机制
图2 OceanStor分布式存储统一鉴权机制
2.配额和Qos能力
一套云化存储池对接多个计算集群,除鉴权和访问隔离外,还要考虑不同计算集群的资源抢占问题。一个计算集群占用的存储空间过高,或者消耗的性能过高,必然影响到其他计算集群的正常运行,这就要求云化存储池具备一定的配额和Qos能力。
OceanStor分布式存储支持租户级和命名空间级配额,可以有效控制不同层级用户的空间占用;同时支持精细化控制的Qos能力,可以针对不同优先级的租户和命名空间提供差异化的服务,从而保障高优先级的业务能够获得最优的服务质量。
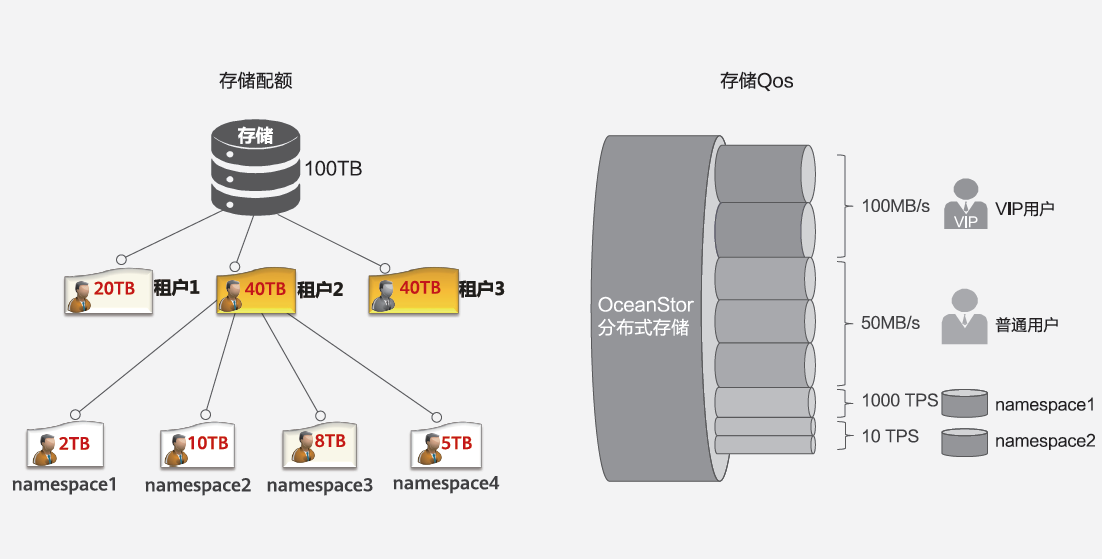 图3 OceanStor分布式存储配额和Qos
图3 OceanStor分布式存储配额和Qos
3.原生HDFS接口
一套云化存储池对接多个计算集群,不同大数据计算集群使用的Hadoop组件可能是不同的,这就要求云化存储池不仅能提供HDFS接口,还要保证对不同Hadoop组件的兼容性。以Ceph为代表的开源分布式存储,多使用S3A接口来实现HDFS协议的对接,但S3A不支持append、flush()、hflush()等接口,这就导致很多Hadoop组件对接上均存在重要限制。
OceanStor分布式存储对外可提供原生HDFS接口,无缝兼容FusionInsight、Cloudra、HortonWorks等主流大数据平台的不同组件,为对接不同计算集群的多样化组件奠定了坚实基础。
4.极致可靠
一套云化存储池对接多个计算集群,相当于把所有鸡蛋放到了一个篮子了,这就要求放鸡蛋的篮子是极致可靠的。
OceanStor分布式存储采用了一系列机制来保障系统的极致可靠,让用户使的如意,用的放心:
- 全对称分布式NameNode,配合EC(Erasure Code)数据保护机制,单存储池最大容忍4个存储节点故障,既保障了系统的可靠性,又消除了性能瓶颈。
- 数据端到端DIFF校验,配合后台静默数据校验,让数据写入和数据读取永远一致。
- 节点故障下,EC级别自动调整,写业务不降级;节点或硬盘故障下,并行数据重构,高达2TB/小时的数据重构速度,有效避免二次故障。
- 全面的系统亚健康检测,防患于未然。
小结
OceanStor分布式存储专为大数据场景云化存储资源池定制,通过多命名空间、统一鉴权、配额、Qos、原生HDFS、极致可靠能力为云化存储池保驾护航,完美支持多套大数据应用共享存储空间科创板
。

原创文章,作者:dongshuai,如若转载,请注明出处:http://boke.6ke.com.cn/?p=32053
