再见
最近几天没有写教程,但是一直在翻资料。
在昨天,我翻到了一条消息:PhantomJS宣布暂停开发。
最初我是在今日头条上看到的,原标题是“PhantomJS宣布终止开发”。不过,写这篇文章的时候我看了一下,应该是“暂停”(suspending)……万恶的标题党……
北京时间2018年3月4日1:16(时间上面就这么写吧……GitHub也没有标当地时间……),PhantomJS的作者ariya在PhantomJS的GitHub页面的issue #15344中写道:
由于缺乏积极的贡献,我将会存档该项目。
如果将来我们又重新开发这个项目的话,这个项目还会被取出来。
因此,所有的之前的关于PhantomJS 2.5(由 @Vitallium 提起)和PhantomJS 2.1.x(由 @pixiuPL 提起)的计划也会废弃。接下来,为了防止混淆,上述被废弃的版本的源码和二进制包也会被删除。在未来的通知之前,PhantomJS 2.1.1将会是已知最后的稳定版本。
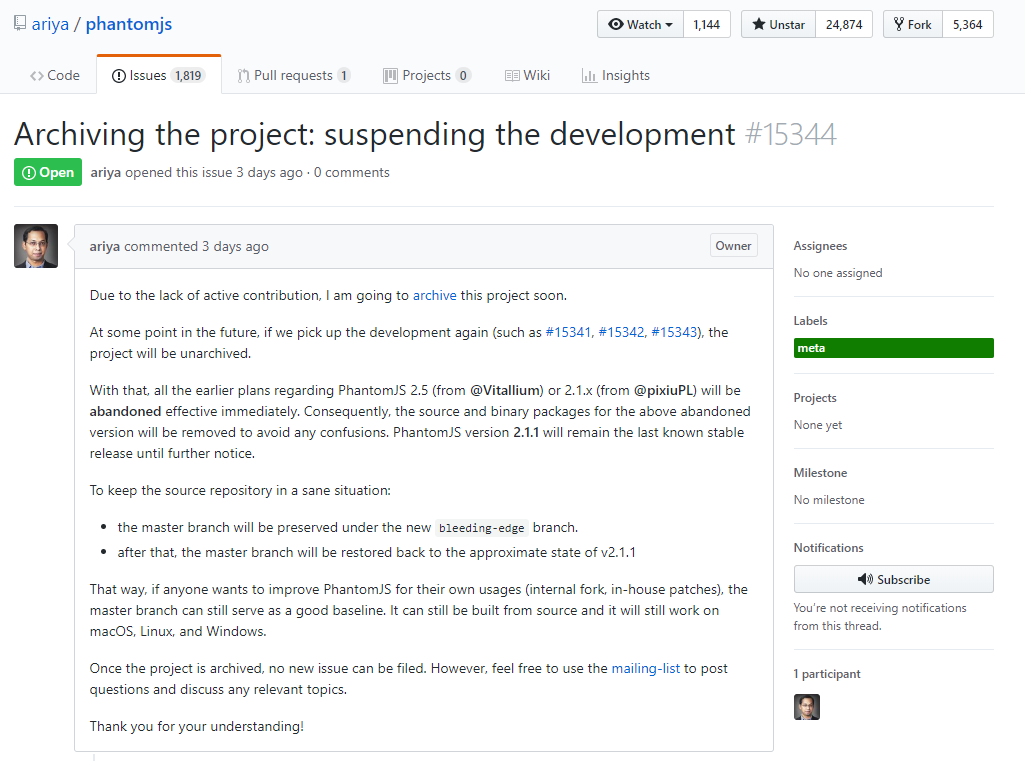

作者ariya宣布暂停开发PhantomJS
不过从开源中国发的文章来看,这背后是开发者内部的矛盾。之前核心开发者之一 Vitaly Slobodin 宣布退出,当时就有人对这个项目感到担忧。然后另一位核心开发者 pixiuPL 发布公开信表示,自己已被迫辞任合作者。这应该就是ariya宣布暂停开发的导火索吧。
PixiuPL 说自己在去年 11 月被 ariya 邀请成为 PhantomJS 项目在 Github 上的 Collaborator,随后开始深入研究 PJS 的源码,并进行 PR 合并、Issues 处理 、新版本发布等工作。近日,由于他在开发过程中遇到了需要访问项目设置权限的问题,随后在 Skype 和邮件上多次联系 ariya ,但均未得到回复(即使对方在线)。
在公开信发布后的 3 月 4 日,pixiuPL 补充道,ariya 已通过 Skype 回复了他,但对于他接管项目的建议感到不愉快。ariya 似乎更愿意关闭项目,并批评 pixiuPL 创建了 PJS 的内部分支(在 GitHub 之外)。
大牛之间的矛盾我也就不多加评论了,毕竟也不是非常清楚情况。不过PhantomJS这款工具在Python爬虫中可是非常有名的。它是一个无头(Headless,无界面,使用脚本进行操作)浏览器,可以进行模拟登录等操作,以便爬取需要登录的网站。我当时做QQ空间的爬虫的时候就接触到了它。想想还是比较惋惜的。
暂停开发的话,可以用别的工具啊。在开源中国的报道下面的评论中,我也知道谷歌的Chrome就有无头模式。
于是我就想在闲的时候写一下关于爬虫浏览器转变的文章。不过,今天我看到的一条消息,比之前看到的还要震惊。
今天本地调试基于Selenium+PhantomJS的动态爬虫程序顺利结束后,着手部署到服务器上,刚买的热乎的京东云,噼里啪啦一顿安装环境,最后跑的时候报了这么个错误:
UserWarning: Selenium support for PhantomJS has been deprecated, please use headless versions of Chrome or Firefox instead运用我考了五遍才飘过的六级英语定睛一看,这个意思是说,新版本的Selenium不再支持PhantomJS了,请使用Chrome或Firefox的无头版本来替代。脑瓜里瞬间响起了这首歌的旋律,简直不能接受,凭什么就把我们PhantomJS抛弃了(╯‵□′)╯︵┻━┻。
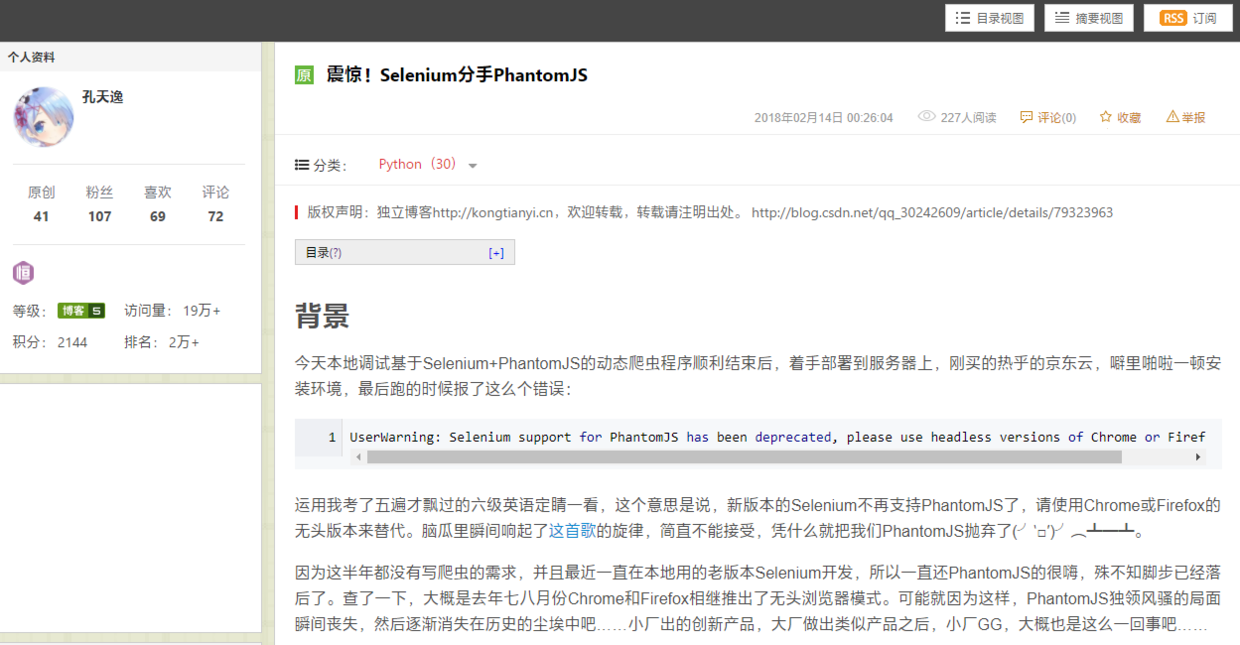
CSDN上的“孔天逸”关于新版本的Selenium不再支持PhantomJS的文章
看来是我火星了……原来Selenium早就准备不支持PhantomJS了。不过作者也说了,可能是因为Firefox和Chrome都带了无头模式,导致PhantomJS的优势瞬间消失了……
这么一说,PhantomJS其实挺惨的……内有内斗,外有打压,搞得众叛亲离(滑稽)。
替代
CSDN上的孔天逸从Mozilla上提供了Selenium+Headless Firefox在Python上实现的方法:
from selenium.webdriver import Firefox
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.firefox.options import Options
from selenium.webdriver.support import expected_conditions as expected
from selenium.webdriver.support.wait import WebDriverWait
if __name__ == “__main__”:
options = Options()
options.add_argument(‘-headless’) # 无头参数
driver = Firefox(executable_path=’geckodriver’, firefox_options=options) # 配了环境变量第一个参数就可以省了,不然传绝对路径
wait = WebDriverWait(driver, timeout=10)
driver.get(‘http://www.google.com’)
wait.until(expected.visibility_of_element_located((By.NAME, ‘q’))).send_keys(‘headless firefox’ + Keys.ENTER)
wait.until(expected.visibility_of_element_located((By.CSS_SELECTOR, ‘#ires a’))).click()
print(driver.page_source)
driver.quit()
作者也说了,本地要有Firefox;本地要有geckodriver,最好再配置一下环境变量;别每下载一个网页实例化一个webdriver(Firefox or Chrome)然后就close()掉,实例化webdriver的时间也是时间~推荐将下载器做成单例类或将webdirver做类变量。
对于Chrome,博客园上的zhuxiaoxi提供了解决方案(需要安装chromedriver):
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
chrome_options = Options()
chrome_options.add_argument(‘–headless’)
chrome_options.add_argument(‘–disable-gpu’)
driver = webdriver.Chrome(chrome_options=chrome_options)
driver.get(“https://cnblogs.com/”)
大家可以按需使用。
结语
我写这篇文章的目的就是想说一下,该换浏览器了。
目前许多关于Python爬虫的教程都还是使用PhantomJS进行讲解的,现在PhantomJS已死,有事请用Chrome或者是Firefox。
目前许多关于Python爬虫的教程都还是使用PhantomJS进行讲解的
(我写这篇文章的时候,居然看到一个14小时前在某个头条号发的关于PhantomJS的教程……不知道该说什么好……)
参考资料
- Archiving the project: suspending the development · Issue #15344 · ariya/phantomjs
- 因内部闹矛盾,PhantomJS 宣布封存归档暂停开发 – 开源中国社区
- 震惊!Selenium分手PhantomJS – CSDN博客
- PhantomJS在Selenium中被标记为过时的应对措施 – zhuxiaoxi – 博客园
原创文章,作者:董 宝山,如若转载,请注明出处:http://boke.6ke.com.cn/?p=7769
